Alan Kay hardly needs a presentation, so i won’t waste your time before pointing out to his latest interview, where he talks with Allan E. Alter about the current computing landscape. As you may expect from a visionary such as Kay, he is not exactly happy with what he sees, and is currently working in his Viewpoints Research Institute to try and invent the future of programming. Besides his involvement in the “One Laptop per Child” project, Kay and coworkers have recently been awarded a NFS grant to develop their ideas on how a better programming platform should be. If you’re curious (and who would not!), you can read some of the details of their amazing plans in the proposal they submitted to the NFS: Steps Towards the Reinvention of Programming. This proposal for the future starts by trying to recover the best from the past, particularly the seemingly forgotten ideas of another visionary, Doug Engelbart. As Kay rightly points out during the interview,
[Most of those ideas] were written down 40 years ago by Engelbart. But in the last few years I’ve been asking computer scientists and programmers whether they’ve ever typed E-N-G-E-L-B-A-R-T into Google-and none of them have. I don’t think you could find a physicist who has not gone back and tried to find out what Newton actually did. It’s unimaginable. Yet the computing profession acts as if there isn’t anything to learn from the past, so most people haven’t gone back and referenced what Engelbart thought.
The reinventing programming project tries to change this situation with some interesting proposals. Their envisioned system would put forward the lessons drawn from Squeak and Etoys towards the creation of a fully introspective environment which can be understood completely by its users; actually, a system which guides programmers to full disclosure of its innards. In Kay and coworkers’ words:
This anticipates one of the 21st century destinies for personal computing: a real computer literacy that is analogous to the reading and writing fluencies of print literacy, where all users will be able to understand and make ideas from dynamic computer representations. This will require a new approach to programming. […] This will eventually require this system to go beyond being reflective to being introspective via a self-ontology. This can be done gradually without interfering with the rest of the implementation.
So, simplicity is key, and they purport to write such a system in a mere 20K LOC. To that end, they propose a sort of great unification theory of particles (homogeneous, extensible objects) and fields (the messages exchanged by myriad objects)—well, yes, it’s just a metaphor, but you can see it in action in the paper, applied to images and animations. The report also explains how the physical metaphor is completed with a proper simulation of the concept of time. As for introspection, inspiration comes, quite naturally, from Lisp:
What was wonderful about this [John McCarthy’s] approach is that it was incredibly powerful and wide-ranging, yet was tiny, and only had one or two points of failure which would cause all of it to “fail fast” if the reasoning was faulty. Or, if the reasoning was OK, then the result would be a very quick whole system of great expressive power. (John’s reasoning was OK.) In the early 70s two of us used this approach to get the first version of Smalltalk going in just a few weeks: one of us did what John did, but with objects, and the other did what Steve Russell did. The result was a new powerful wide-ranging programming language and system seemingly by magic.
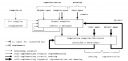 Lest anyone thinks that all of this is just a loosely knitted bag of metaphors and wishful thinking, the report gives some technical detail on an actual implementation of some of these ideas. Albert is a bootstrapper that is able in a few hundreds of lines of code to make a kernel for Squeak that runs nine times faster than existing interpreters. The bootstrap process looks fascinating:
Lest anyone thinks that all of this is just a loosely knitted bag of metaphors and wishful thinking, the report gives some technical detail on an actual implementation of some of these ideas. Albert is a bootstrapper that is able in a few hundreds of lines of code to make a kernel for Squeak that runs nine times faster than existing interpreters. The bootstrap process looks fascinating:
A disposable compiler (written in C++) implements a simple message-passing object-oriented language in which a specification-based Object compiler (implementing the same language) is implemented. The system is now self-implementing but still static. A dynamic expression compiler/evaluator is then implemented using the static compiler and used to replace the static messaging mechanisms with dynamic equivalents. The system is now self-describing and dynamic hence pervasively late-bound: its entire implementation is visible to, and dynamically modifiable by, the end user.
Again, the proposal gives a bit more detail, but i’m not sure i’m understanding it fully: if anyone knows if/where Albert’s code is available, please chime in!
Not that i agree 100% with all the ideas in the report (and, as i said, there’re quite a few i don’t fully grasp), and i’m sure most of you won’t agree with everything either. But it’s definitely worth the effort reading, trying to understand and mulling over Alan Kay’s vision of the future of programming. He knows a bit about these things.
Update: Thanks to Glenn Ehrlich, who in a comment below provides links to learn more about Ian Piumarta’s Albert, also known as Cola/Coke/Pepsi.





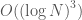 . That means that we go from exponential to polynomial time when going from classical to quantum for this particular problem (and related ones: the
. That means that we go from exponential to polynomial time when going from classical to quantum for this particular problem (and related ones: the 

